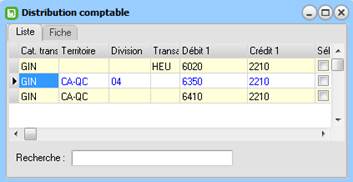
Le principe d’utilisation de la table de distribution est très simple. Lors de la génération des transactions, le système analyse dans un premier temps quelle est la combinaison « Niveau, Territoire, Division, Catégorie de modificateur, Modificateur, Taxe, Code de transaction » impliquée dans la transaction.
Ensuite, il recherche la même combinaison à la table de distribution. S’il la trouve, il génère les écritures et les transactions comptables nécessaires selon l’information contenue aux champs « Débit », « Crédit » et « Cn ».
Si le système ne trouve pas de combinaison identique, il utilise la combinaison qui se rapproche le plus à la table de distribution et génère ensuite les écritures comptables selon cette combinaison.
Pour trouver la meilleure distribution possible, le système procède de la droite vers la gauche, c'est-à-dire en partant du code de transaction en combinant progressivement les autres informations (Taxe, Modificateur, Catégorie de modificateur, Division, Territoire, Niveau) afin d'identifier la distribution applicable. Le principe de base étant ici de procéder le plus possible du particulier vers le général afin d'optimiser la précision de la distribution comptable par rapport au contenu de la transaction.
Voici un exemple de la logique de la distribution comptable. Voici d’abord la distribution comptable :
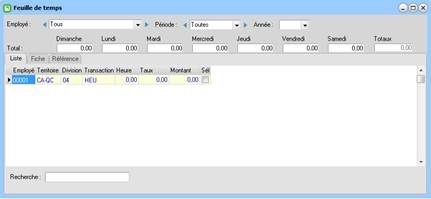
Voici une transaction de feuille de temps :
Voici comment c'est généré la distribution comptable pour cette transaction de GIN-Gain :
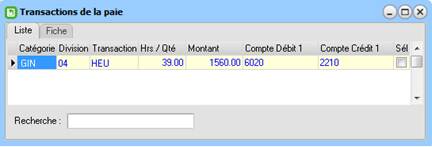
Toutes les distributions sont pertinentes pour la feuille de temps de l'exemple ci-haut, mais on voit que la donnée la plus spécifique est à droite au niveau de la distribution comptable, soit ici, le code de transaction HEU pour le GIN.